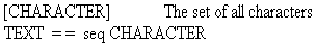
A block of HTML text can be presented to the user in two different ways. Two windows can be opened for each block of text; a browser window to display it in HTML format and an editor window to display (and edit) the actual HTML text itself.
A block of HTML text is stored as a sequence of characters.
The text is contained by an HtmlFile object which can create one viewer window and one editor window to display it.

In its initial state, an HtmlFile contains no text and has no opened windows.
The following schema allows the text in an HtmlFile to be updated. This may be used directly, to reflect changes to the text made in the editor window for example, or as part of the procedure for creating or retrieving a new HTML file (described below).

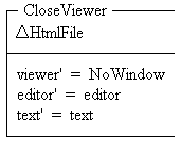
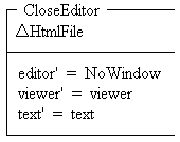
These schemas are used to open and close the viewer and editor windows of an HtmlFile.


The following schemas are used when a new block of HTML text is created or retrieved into a viewer or editor window. Since both of the windows in an HtmlFile must refer to the same block of text, a window will be closed before loading a new block of text into its partner window.

The text in an HTML file is considered to consist of sequences of characters which represent HTML tags (delimited with < and >) interleaved with sequences representing plain text. For each sequence in the text an HtmlReader selects a 'tag-object' from a given list which performs some function on a given HTML output component. Each tag-object in the resulting list can then be activated in turn to produce the output for a page.
A block of HTML text is presented to an HtmlReader as a sequence of characters.

Sequences of characters within the text that are delimited by left and right angled-brackets are interpreted as HTML tags. All other character sequences are treated as blocks of plain text.

The tag-objects created to handle HTML tags are all extensions of a common generic type. A special object of this type is provided to handle sequences of characters which do not represent recognized HTML tags (ie. plain-text and unsupported tags).
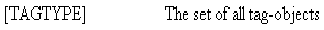
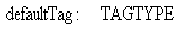
Each HTML tag is identified by the sequence of characters (or 'string') immediately following the opening bracket of the tag. An HtmlReader compares each item in a list of recognized ID strings with this ID string. If a match is found, the corresponding item from a list of tag-objects is selected.

After processing a block of HTML text, an HtmlReader contains a list of tag-objects which represents that text and can be used to produce its output. In its initial state, an HtmlReader contains an empty tag-object list.


The first step in adding a tag-object to the list is to determine whether the current text begins with an HTML tag or a block of plain-text. If the text begins with a left angled-bracket and contains a right angled-bracket at some other position, it is assumed to be an HTML tag.

The type of an HTML tag must then be determined so that the relevant tag-object can be created to handle it. If an ID string is found which matches the ID string in the tag, an instance of the corresponding tag-object is appended to the list in the HtmlReader.
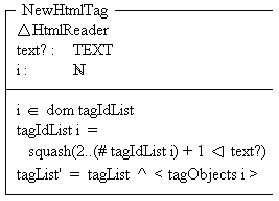
If the text is not delimited by angled-brackets or is not a recognized HTML tag, a default tag-object is appended to the HtmlReader list.

The process performed by an HtmlReader can thus be summarised.


The TAGTYPE type defines each of the recognized tag-objects. In the specification of the HTML text-processing object (above), TAGTYPE was defined as a generic basic type to accommodate any type of tag-object. In this part of the specification TAGTYPE is a free type which explicitly defines each recognized tag-object.

The TagType schema defines the basic attributes associated with each object of type TAGTYPE. Each object obviously has a type and also the ability to indicate whether it represents an opening-tag or a closing-tag. The lTagType and dlTagType schemas are derivations of TagType. They add some special features used by tag-objects which create lists.

The Text and Image schemas define objects which represent blocks of textual and graphical output data.

The values of incIndent and decIndent are the steps used to increment and decrement page indentation.

The bulletChar character is used to bullet un-ordered lists.
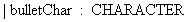

The following schemas are used to modify the various flag settings for an HtmlPage object.









The following schemas modify the font settings for text output.



The nextline schema advances the current output location (represented by xpos and ypos) to the start of the next line. The lineTop variable is used to keep track of the top of the line, since ypos may be modified when aligning text with adjacent images. The newLines variable counts the number of calls to nextline without an intervening use of drawText or drawImage and is used to filter out any redundant empty lines.
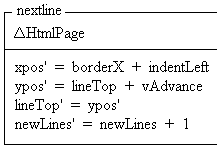
Most tag-objects do not use the nextline schema directly. Instead, they use either the newline schema or the newpara schema so that redundant empty lines can be ignored.


The drawText and drawImage schemas draw text and images at the current location on the page and then update the current location accordingly. The newLines variable is reset to indicate a non-empty line.


The following schemas add values to the indentation offsets from the left and right margins.


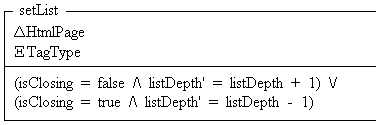
The setList schema is used when starting or ending a list.
The setLink schema is used when starting or ending an area of the page which is to be a hypertext link.

The setBullet schema determines whether to use a bullet character or an item-number for an item in a list.

The setTerm and setDefinition schemas are used when starting a new item in a definition-list (a term or a definition).



